
Architecting the agentic SDLC
Moving beyond the copilot baseline to solve the new constraints of AI-driven engineering
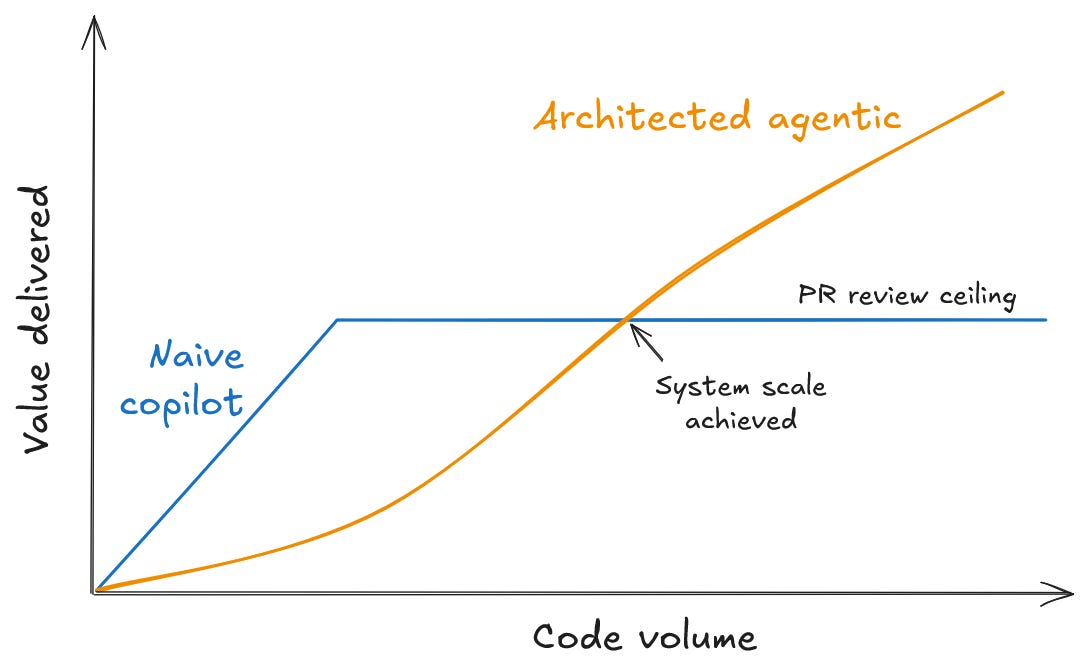
In early 2025, most companies handed out Claude Code or GitHub Copilot licences expecting a revolution. Today, leaders who stop there are simply treating AI as a typing upgrade. Relying on this copilot-era baseline misses the potential of AI while increasing the risks.
Teams will generate code faster than they can review it, creating a PR overload that will trigger cognitive fatigue. Engineers, overwhelmed by the volume, will start rubber-stamping reviews.
The operational danger with AI is over-trust. Rubber-stamping introduces a silent architectural drift that bypasses traditional guardrails, degrading the integrity of the code. By the time the company realises, it has already damaged key business metrics.
Shift-left prototyping
In an agentic SDLC, product managers no longer wait for designers to prioritise requests or engineers to build a POC. Multi-modal models allow them to generate disposable prototypes, delivering even higher value when linked to the company’s context and design systems.
This is a systemic change. As the cost of a prototype drops to near zero, their number will spike. While this speeds up product discovery, it introduces a big risk: the pressure to release mock-ups. Leaders must build a culture that encourages rapid exploration while enforcing a hard boundary: these mock-ups never go to production. But culture is often not enough. Engineering must implement hard CI/CD boundaries that block prototype deployment, and partner with Product to define a strict process from disposable mock-up to production-ready architecture.
From code creator to system editor
The role of engineers moves from writing code to acting as a human-in-the-loop (HITL) assessing risk, guiding AI agents to generate PRs that align with the team’s approved architectural patterns.
Human engineers make assumptions based on unwritten specifications, consider context from leadership presentations, and flag edge cases during implementation. AI agents only build what is documented, they do not infer business context or edge cases. This is a massive shift in the SDLC. Pointing an internal MCP server at stale documentation or dropping an agents.md file into a repository is not enough. Product and senior engineering must carry the extra load of specifying architectural direction and edge cases upfront.
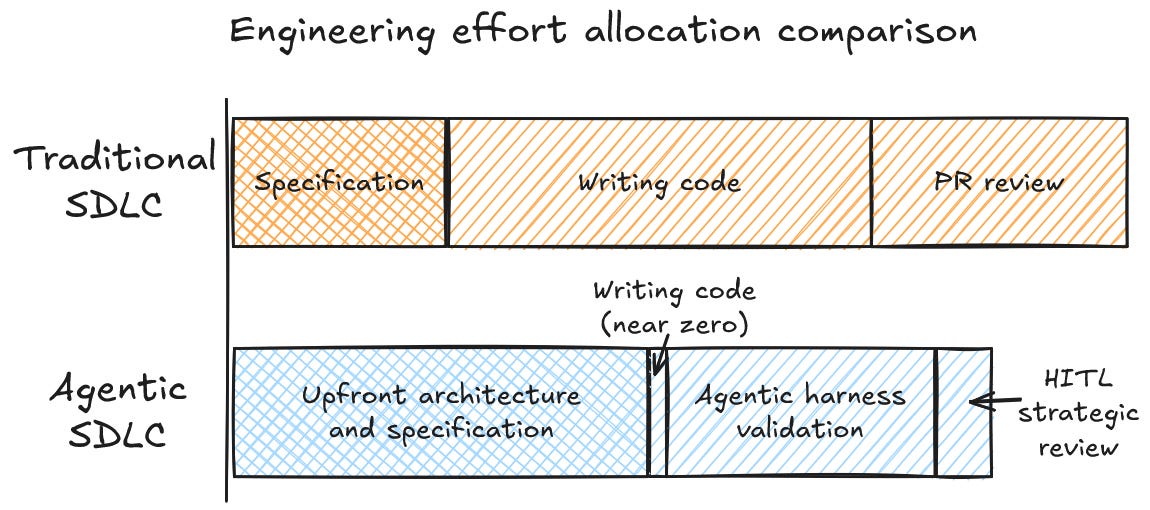
Because static analysis and unit tests are not enough to catch hallucinations, the pipeline needs multi-agent validation before the human-in-the-loop stage. Engineering teams can no longer just maintain standard CI/CD pipelines, they must build an agentic harness: a layered verification infrastructure of cross-model checks, semantic linters, and strict architectural constraints. Inside this harness, an independent agent scans the generated PR for hallucinated dependencies, loss of architectural context, or deviations from the defined guidelines. However, this introduces new trade-offs: it increases pipeline execution time and token spend. Engineering leaders must balance this against the cost of human review fatigue. This ensures the HITL focuses on validating strategic intent rather than chasing down the agent’s mistakes. Line-by-line code reading is no longer the default verification method, it becomes an escalation path only for sensitive areas like security, severe architectural drift, or complex incident debugging.
System health and the token economy
Higher PR throughput combined with higher hallucination risk inevitably increases the Change Failure Rate (CFR). Without a corresponding decrease in Mean Time To Recovery (MTTR), this delivery speed will cause customer disruption. As we move from human pace copilot usage to fully agentic pipelines, system health is defined by the tension between these two metrics.
This does not mean that defects have less impact simply because an agent can draft a fix faster; a critical failure is still disastrous. However, because agentic velocity multiplies the absolute number of deployments, reducing MTTR shifts from a standard operational goal to a critical survival requirement.
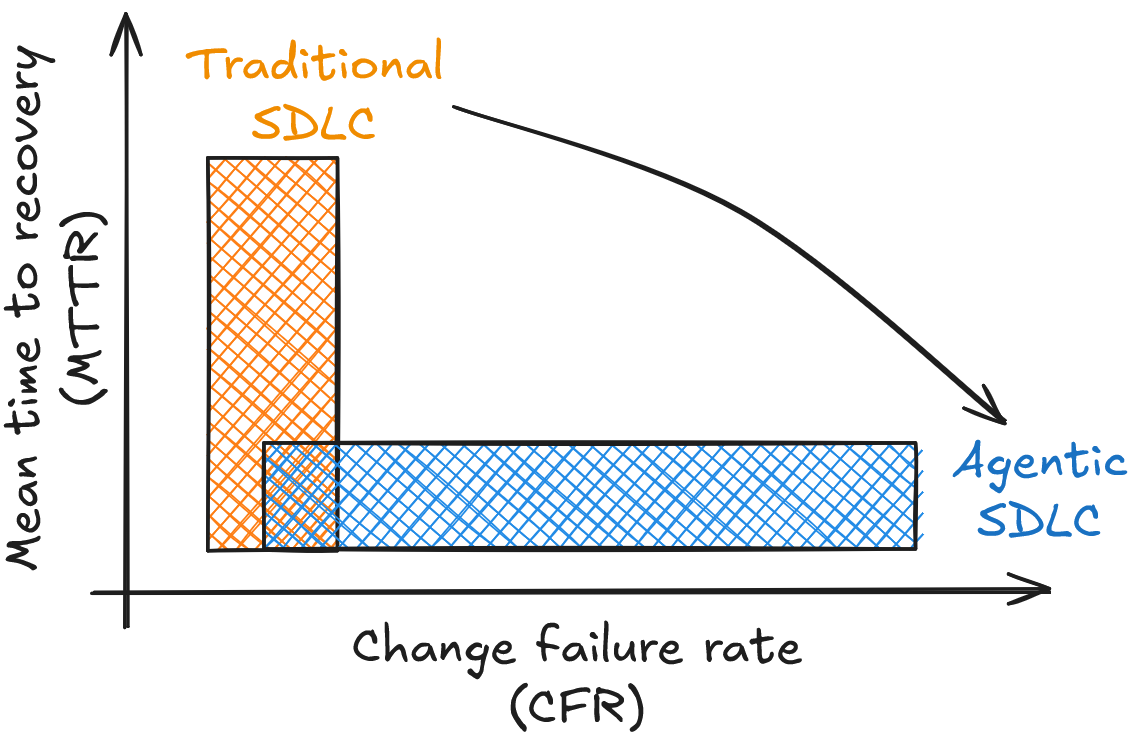
Because a low MTTR is the safety net, the system requires automated incident orchestration. The pipeline uses external agentic tools, such as incident.io or Rootly, to perform semantic log analysis and share the root-cause output directly with the PR-drafting agents. Engineers then review these remediation PRs and control the timing of their deployment.
While tokens are getting cheaper, newer models are becoming increasingly complex. Engineering leaders must track token consumption with the same rigour they apply to cloud infrastructure spend. Project budgets account for the specific model complexity required. If the token cost of generating boilerplate is higher than the engineering time saved, the workflow gets deprecated.
The new reality of pipeline bottlenecks
As prototyping and code generation get faster, the bottleneck moves downstream. Concurrency limits on the CI/CD pipeline, and the cognitive load on the human-in-the-loop merge gate become the new constraints.
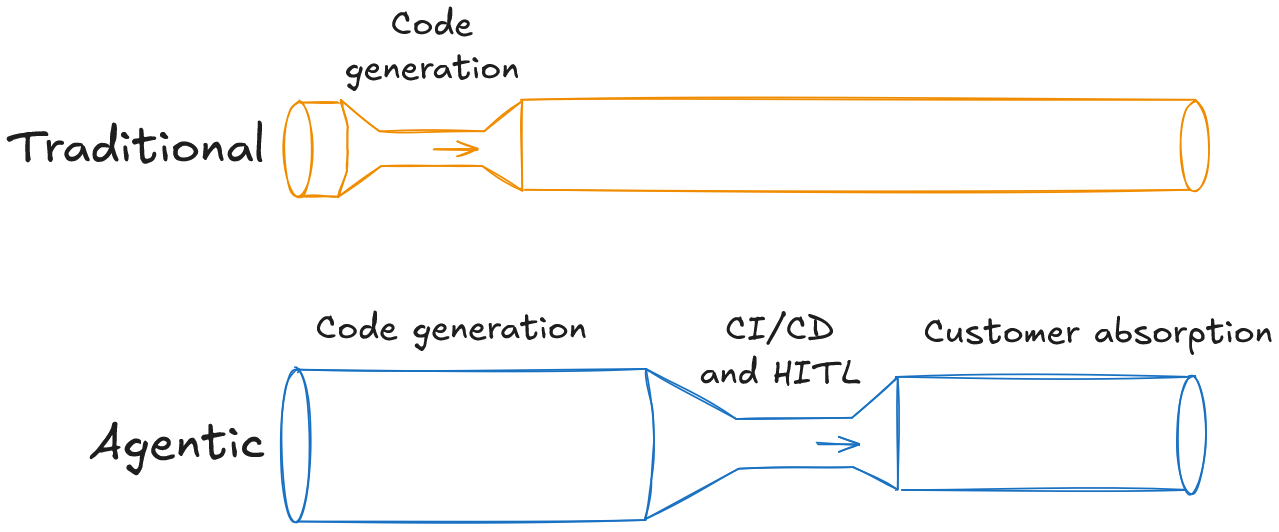
Even if engineering achieves near-infinite delivery speed, the final limit is how fast customers can absorb new features and how much real-user UX research the business can do to validate them. To survive this shift and double engineering impact, leaders must stop optimising only for output volume and start building the feedback loops required to measure real-world impact.
If there is a sea of changes coming in the way of the HITL, who do we know what is worth reviewing and what is fine to let flow as is?