
Strategic re-architecture, moving beyond the “black hole” fear
A 3-phase playbook for turning legacy constraints into business velocity, without the capital drain
Discussing large-scale re-architecture often triggers an uneasy feeling. We all have seen those black-hole projects: migrations that use huge amounts of capital, drag on for quarters (or years!), and eat leadership trust. This is not where we want to be.
But the problem needs to be addressed before it becomes a crisis. Strategic re-architecture is not about cleaning code, it’s about ensuring alignment with the architecture strategy and the company’s vision
You probably have faced it before: that system that is getting increasingly difficult to maintain, slow to change and the teams keep complaining about. But when is the right time to re-architect a system? Success requires to distinguish between noise and signal. Noise is CV driven development or vague sentiment. The real signals are about the business: when the architecture no longer supports the company’s vision, when a metric supports that the system is impacting velocity, or when maintenance and incident management take most capacity for new value.

Phase 1: The strategy
With the problem defined, resist the urge to start coding immediately. Conduct discovery interviews not just with engineering consumers, but also with commercial stakeholders, to understand the gap between the system’s current capabilities and the market’s future needs.
Define the team topologies
To deliver at pace, make sure that you avoid the “design by committee” trap. Instead, structure the organisation into clear groups:
Steering group: A cross-functional group of 3-4 leaders from Product, Engineering (you), Delivery, Commercial, Design, etc. to ensure the technical work stays aligned with the business priorities
Builder teams (2-3 teams): The core group to define and implement the new architecture
Consumer teams (3-30 teams): The internal customers who will migrate to the new system
The method: Strangler Fig
Big bang releases reduce trust because they are a money black hole without a visible return. I use the Strangler Fig pattern instead, to deliver incremental value. The main benefit is not the technical part, it’s how it helps with mitigating risks by releasing and validating the business case incrementally, which will help to maintain senior leadership confidence. If priorities change, we still have a working system with the value delivered so far, rather than a half-built sports car with no engine.
Staff+ leverage
Finally, rely on your Staff+ engineers to help shape the design and the scope.
Ruthless descoping: We must define the trade-offs between feature parity and delivery speed. If a legacy feature adds 20% complexity but only 1% value, I empower Staff+ engineers to reject it or move to a Fast Followers list.
Saying “no”: They must challenge stakeholders’ requirements (not only Product’s) that inflate the scope unnecessarily, making sure that we build only what is needed for the future state, not copying the current state or previous requirements.
Building the business case and securing buy-in
Securing buy-in isn’t about re-architecting. It’s about turning your technical plan into a compelling business case.
Focus on your audience: Identify the budget holder, as well as anyone who might need convincing. Be empathetic, understand their concerns, and the impact of this proposal on their own strategy.
The framing: Frame the problem using their language. Use terms like “blocking market expansion” or “opportunity cost”. Make sure that it gives them tools to support it when sharing with their colleagues, who might be impacted indirectly.
The cost of inaction: Make the cost of inaction clear. Turn the positive impact of your proposal into the revenue the business will lose if you do nothing.
Multiple options: Offer 2-3 options, with a clear preferred approach. This shows that you thought the problem through. Include target metrics, how you will track progress, timelines, and a list of known risks and how you plan to manage them.
Phase 2: The execution
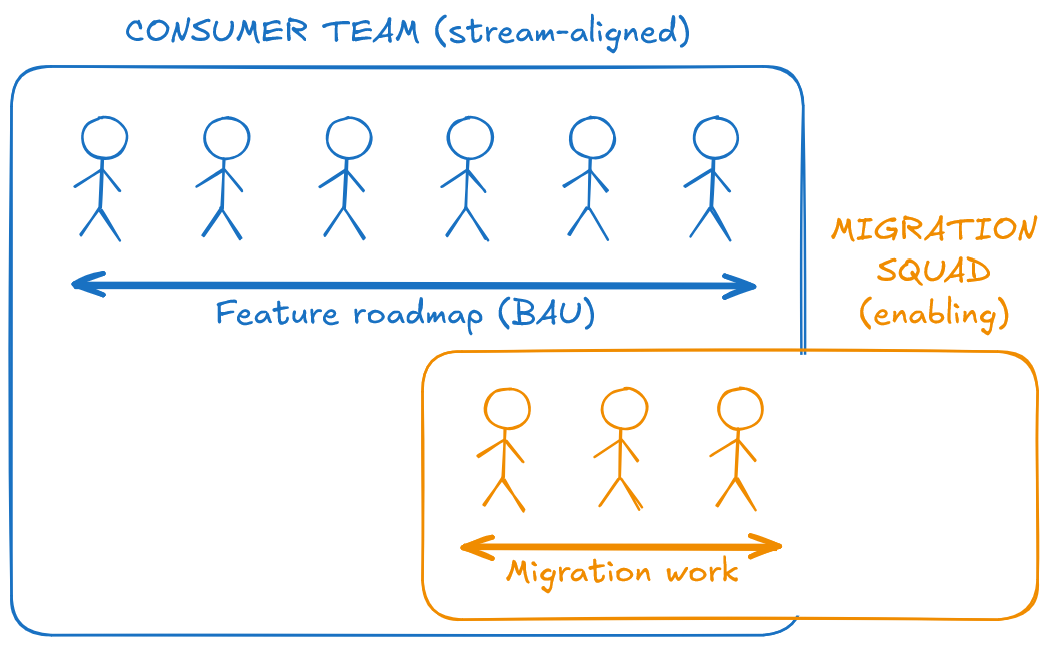
Consumer teams have their own pressure and deadlines, so they will not voluntarily prioritise the migration unless friction is removed. To succeed, you must treat the migration as an internal product launch.
Driving adoption
We cannot rely on authority or endless road-shows to drive migration to the new system. Pushing a change will create friction, so instead I treat the new system as a product and focus on creating a “pull” mechanism through the following:
The paved road: We invested in clear documentation and tooling. By automating 80% of the work, you lower teams’ resistance.
Social proof: We didn’t target all teams at once, we focused on a high-influence team. We aligned the migration with their goals. We proved that the new system improved their deployment frequency and reduced their on-call noise. Once they share the positive impact, other teams will start asking to migrate.
Senior leadership sponsorship: Bottom-up adoption is powerful, but not enough. Senior leadership sponsorship is not a one-off, they must keep reminding the organisation that the migration is a critical business objective, not optional work. We used company all-hands to share progress and celebrate the teams that have completed their migration, reinforcing the cultural message.
Resource injection
The most common failure is competition for limited resources. Teams will say that they don’t have capacity. Instead of negotiating for small bits of time, focus on solving the capacity issue.
Be empathetic: Adjust the Builder team’s roadmap to accommodate the Consumer teams’ deadlines where possible. This is a deliberate trade-off: we sacrifice short-term output to secure long-term outcome.
Create a migration squad: If a team is blocked, inject capacity. Either secure a temporary squad of contractors or use members from the Builder team to deliver the migration work for the Consumer teams. This will remove the resourcing argument and help stick to your timeline instead of theirs.
Handling cross-domain friction
Even with resources injected, you will face friction where a Consumer team’s leadership prioritises their own roadmap over the migration. Since these leaders are often your peers and sit outside the Steering Group, you cannot simply overrule them.
Radical transparency: Do not let the pushback stay private. If a Domain Leader refuses to prioritise the migration, publish this in the Steering Group status report. Frame it neutrally but clearly: “Domain X is currently blocked due to conflicting roadmap priorities. Impact: Migration delayed by 4 weeks, with running costs increased by £15k”.
The Sponsor’s role: If the deadlock persists, you must escalate the issue to the sponsor, instead of incurring an even bigger cost of delay. They will then decide: either mandate the migration (overruling the Domain Leader) or accept the delay (and the cost). This forces a business decision rather than a personal argument.
Phase 3: Governance
Safety protocols
Preparing for live traffic requires decoupling deployment (code in production) from release (traffic through the new code). To mitigate risk, you must enforce safety protocols.
Make feature toggles mandatory for instant roll-backs, use shadow traffic to test under real load, and ramp up real traffic with canary releases. For new functionality, use A/B testing to validate the added value.
Managing the long tail
The final ~5% of a migration often provides diminishing returns. Do not let this block the completion of the project unless the trade-off is in critical areas like security. Once the core value has been delivered, identify the pending low-value items and track them as technical debt to be addressed later. This allows you to close the project and have the Builder teams focus on new strategic work.
Visibility and reporting
Avoid manual spreadsheet tracking where possible. Instead, build automated dashboards (Jira, DataDog, Grafana…) to track real-time progress. However, senior leadership usually doesn’t need a high level of detail, they prefer a consolidated view. In this case, share a fortnightly summary with a cross-functional steering group, highlighting progress, risks and required actions, with links to the live data dashboards.
Key metrics to track
Migration velocity: % of traffic migrated
Domain KPIs: Monitoring existing business metrics to ensure there are no regressions during the switch
System health: Number of incidents (legacy vs new)
Business impact: The specific metrics that triggered re-architecting the system, e.g. conversion rate in a new region
Conclusion
This process is not about code, it is about making sure that the technology supports the company’s vision. By removing the friction between the legacy system and the business needs, you remove constraints and become more agile.
I applied this exact approach to migrate a core legacy system involving 20+ consumer teams. By treating the migration as an internal product launch and using the migration squad tactic to unblock teams, we achieved a 40% increase in new orders and a 70% reduction in infrastructure costs, while cutting production incidents by 90%.
Re-architecting is not only a technical task, it is a strategic decision to unlock future revenue.